S3 Batch Operations - Lambda

Introduction
I recently encountered the task of modifying and relocating millions of objects within an S3 bucket. Using Glue or EMR for this task would require significant effort and time, and these solutions are not ideally suited for storage management tasks. Given the large number of objects involved, using a script wasn’t the best approach, leading me to choose S3 Batch Operations as the preferred alternative.
S3 Batch Operations can perform actions across billions of objects and petabytes of data. To accomplish this, we generate a job comprising a list of objects and the corresponding actions we intend to execute. S3 Batch Operations supports several types of operations such as:
- Copy objects
- Invoke AWS Lambda function
- Replace all objects tags
- Delete all objects tags
- Replace access control list
- Restore objects with Batch Operations
- S3 Object Lock retention
- S3 Object Lock legal hold
- Replicating existing objects with S3 Batch Replication
Check the documentation for more information on each operation: Operations supported by S3 Batch Operations
This quick guide will specifically concentrate on triggering an AWS Lambda function through S3 Batch Operations and the essential prerequisites for its functionality. For a more comprehensive understanding, refer to the extensive AWS documentation; this post serves as a quick reference for high-level insights.
Setup
Manifest file
The manifest file serves as a comprehensive list of objects on which you
intend to execute a Lambda function using S3 Batch Operations. It can be a
simple CSV file with the following columns:
bucket, key, version ID. The version ID column is optional and can be left out
if you don’t need it.
Please note that object keys have to defined in the URL form.
For example, if we have an object with the following S3 URI
s3://test/report/date=2023-01-01/id=XYZ/test.snappy.parquet in manifest file we will put its key as report/date%3D2023-01-01/id%3DXYZ/test.snappy.parquet
Also, CSV file should not contain headers.
Therefore, a CSV manifest file should look like:
test,report/date%3D2023-01-01/id%3DXYZ/test_1.snappy.parquet
test,report/date%3D2023-01-01/id%3DXYZ/test_2.snappy.parquet
test,report/date%3D2023-01-01/id%3DXYZ/test_3.snappy.parquet
...
The first column is the bucket name, followed by the object key. Version ID is not needed so we leave third column empty.
Batch Job Role
When setting up an S3 Batch Operations Job, you need to assign an IAM role for the job. This role has to have following permissions:
- Assumed by S3 Batch Operations Service - Trust relationship that allow S3 Batch Operations service to assume this role:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "batchoperations.s3.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
- Read S3 object - This permission allows Job to read manifest file and get
the list of objects. For example broad read permission on
testbucket:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetBucket*",
"s3:GetObject*",
"s3:List*"
],
"Resource": [
"arn:aws:s3:::test/",
"arn:aws:s3:::test/*"
]
}
]
}
-
Write S3 object - This permission allows job to write a report. This report is important since it will give us more information about failed tasks which we can further filter and reprocess.
-
Invoke Lambda function - Allows job to invoke a Lambda function which will process S3 objects:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"lambda:InvokeFunction"
],
"Resource": [
"arn:aws:lambda:us-east-2:123456789012:function:my-function"
]
}
]
}
Lambda function
Event/Response Schema
When creating a Lambda function we have to be aware of the event and response schema. There are two schema versions, if version 1.0 is selected S3 Batch Operations will send the following event:
{
"invocationSchemaVersion": "1.0",
"invocationId": "<invocation-id>",
"job": {
"id": "<job-id>"
},
"tasks": [
{
"taskId": "<task-id>",
"s3Key": "<s3-key-url-form>",
"s3VersionId": "<version-id>",
"s3BucketArn": "<arn-s3-bucket>"
}
]
}
and expects a response in the following form:
{
"invocationSchemaVersion": "1.0",
"treatMissingKeysAs" : "PermanentFailure",
"invocationId" : "<invocation-id>",
"results": [
{
"taskId": "<task-id>",
"resultCode": "<result-code>",
"resultString": "<result-string>"
}
]
}
The <result-code> defines the outcome of the Lambda function and can be:
Succeeded- Task completedTemporaryFailure- Task temporarily failed and will be re-triggered before the job completesPermanentFailure- Task permanently failed and won’t be re-triggered. It will be labeled asfailedin the report
Handler Example
The following code is an example of a Lambda handler that copies an S3 object. Destination object key is dynamically generated based on source object key, which is not possible using an ordinary predefined Copy operation.
import logging
from urllib import parse
import boto3
logger = logging.getLogger(__name__)
logger.setLevel("INFO")
s3 = boto3.client("s3")
def lambda_handler(event, context):
invocation_id = event["invocationId"]
invocation_schema_version = event["invocationSchemaVersion"]
results = []
result_code = None
result_string = None
task = event["tasks"][0]
task_id = task["taskId"]
source_object_key = parse.unquote(task["s3Key"], encoding="utf-8")
source_bucket_name = task["s3BucketArn"].split(":")[-1]
try:
destination_bucket_name = "report-dest"
destination_bucket_key = source_object_key.replace("A", "B")
copy_source = {
"Bucket": source_bucket_name,
"Key": source_object_key,
}
s3.copy(
copy_source,
destination_bucket_name,
destination_object_key,
)
result_code = "Succeeded"
result_string = f"Successfully copied object"
except Exception as error:
result_code = "PermanentFailure"
result_string = str(error)
logger.exception(error)
finally:
results.append(
{
"taskId": task_id,
"resultCode": result_code,
"resultString": result_string,
}
)
return {
"invocationSchemaVersion": invocation_schema_version,
"treatMissingKeysAs": "PermanentFailure",
"invocationId": invocation_id,
"results": results,
}
AWS Console
Creating an S3 Batch Operations Job through AWS Console is pretty straight-forward and is done in 3 steps.
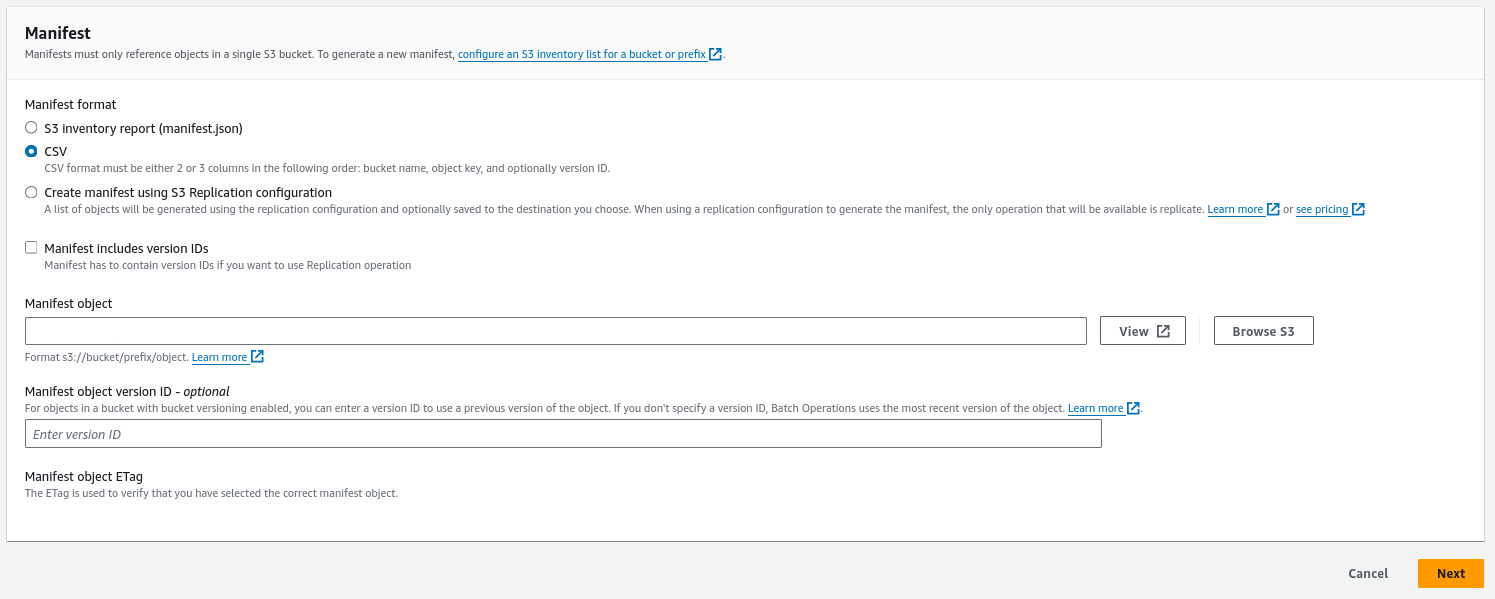
- The first step is to choose a manifest file
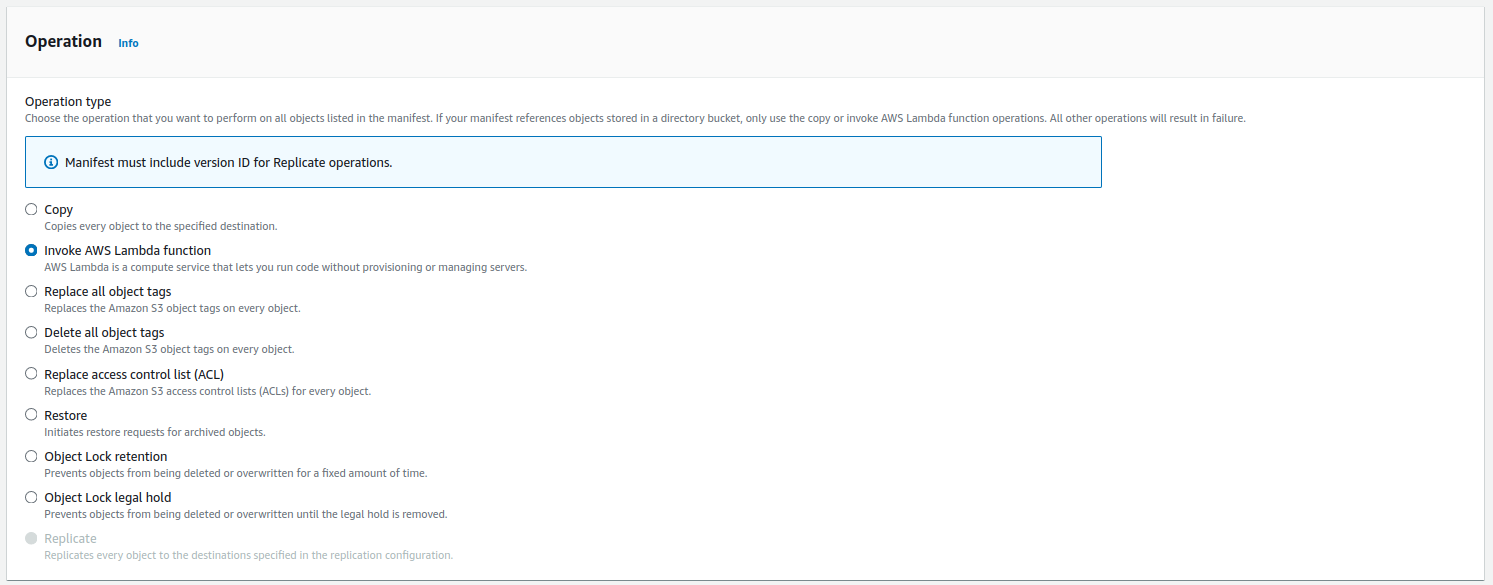
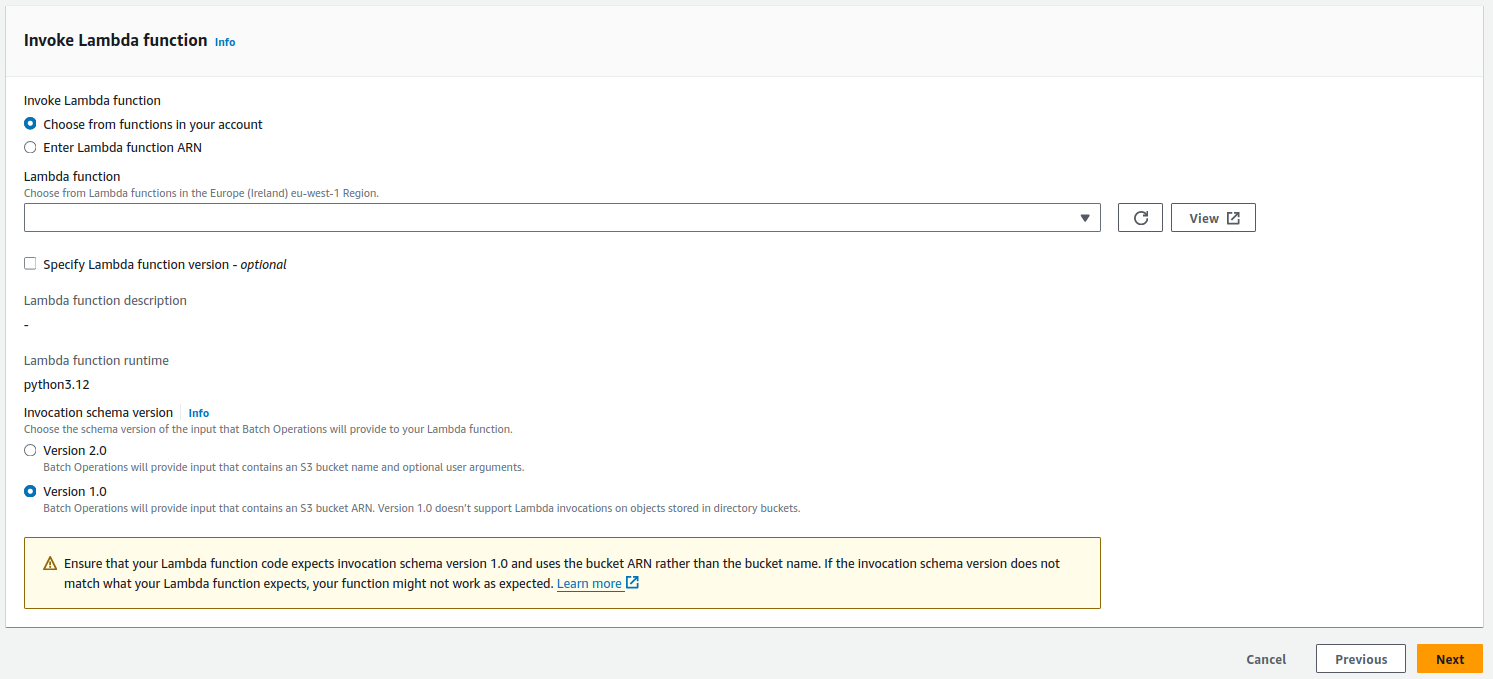
- The second step is to choose an Operation and a Lambda function. Be sure to check Version 1.0 for invocation schema.
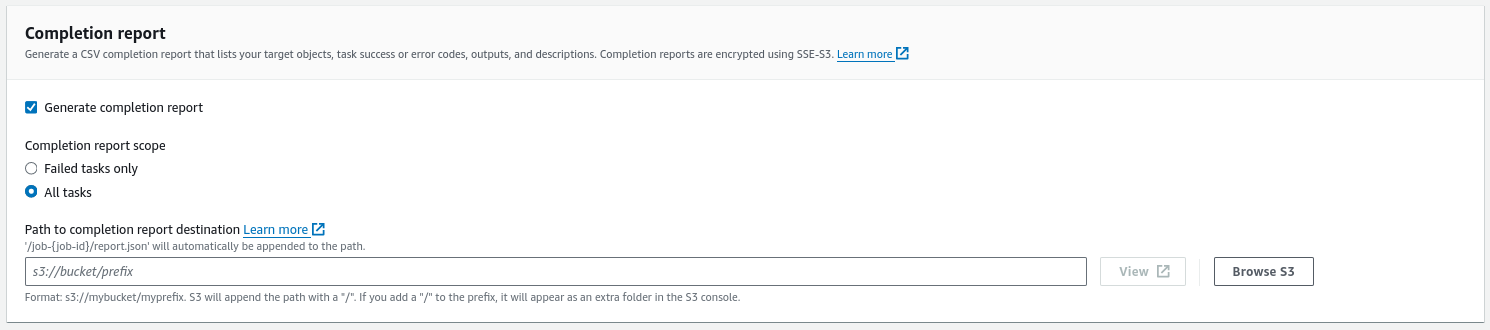
- The last step is to choose a report path and a job role

After creating a job, it will be in the READY state - waiting for you to run it, it
won’t get triggered automatically.
AWS SDK
Creating a job can be also done through code using create_job method
S3Control.Client.create_job(**kwargs).
The same parameters apply, for example:
response = client.create_job(
AccountId='<account-id>',
ConfirmationRequired=False,
Operation={
'LambdaInvoke': {
'FunctionArn': '<lambda-arn>'
},
},
Report={
'Bucket': '<report-bucket>',
'Format': 'Report_CSV_20180820',
'Enabled': True,
'Prefix': '<prefix>',
'ReportScope': 'AllTasks'
},
Manifest={
'Spec': {
'Format': 'S3BatchOperations_CSV_20180820',
'Fields': [ 'Bucket', 'Key']
},
'Location': {
'ObjectArn': '<object-arn>',
'ETag': '<object-etag>'
}
},
Description='<description>',
Priority=10,
RoleArn='<job-role-arn>',
)
The response will be a job ID.
Leave a comment